VisT理解与MindSpore框架下的实现
VisT,作为微软亚洲研究院的杰出成果,引领视频动作识别领域的前沿,其Shifted Window Attention架构奠定了卓越性能的新标准。VisT模型家族包含了Swin3D-Tiny、Swin3D-Small和Swin3D-Base等版本,它们通过3D窗口注意力机制(3D W-MSA)和Swin Transformer Block构建,旨在提供出色的视频帧处理能力。
动作识别怎么统计单类识别精度
1、收集数据、标注数据、训练模型。收集数据:首先需要收集一个包含多个样本的数据集,这些样本属于同一类别。标注数据:其次,对于每个样本,需要将其标注为正确的类别。训练模型:最后,使用机器学习算法训练一个动作识别模型,该模型可以接受视频片段作为输入,并输出相应的类别预测。
2、动作识别基石 从基础出发,视频片段通过采样进行识别,时空特征的深度学习至关重要,它融合了空间特征(Two-Stream CNN、TSN、P3D/I3D/R(2+1)D)和时间特征,构建了视频内容理解的基石。对于时空特征的精细建模,非局部(Non-local)和慢速-快速(Slow-Fast)方法各有千秋。
3、实验数据强有力地证实,这种融合时空与频率特征的TFNet,通过注意力机制的调和,不仅提高了检测的精度,还展示了利用频域信息进行动作识别的潜力。相较于现有最先进的模型,TFNet展现出显著的优势,证明了它在复杂动作检测中的独到之处。然而,传统方法往往过于侧重时空特性,而忽视了频域中蕴含的宝贵信息。
4、人体姿态估计:通过计算机视觉技术,例如深度学习和卷积神经网络(CNN),可以对收集到的视频数据进行人体姿态估计,从而识别学生和教师在课堂上的姿势和动作。动作识别:对人体姿态进行分析后,可以识别出具体的行为,如举手、站立、坐下等。
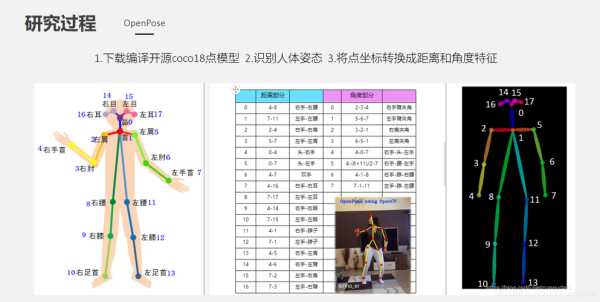
5、基于大规模人体姿态动作数据识别训练,配合摄像头及视觉分析技术,依据身体18个关键点实时进行身体位估计和渲染,实现多线程的多人关键点实时检测,自动捕捉人体姿态。
6、首先,CPU6735支持的动作识别技术包括传统的基于规则的动作识别、基于模式匹配的动作识别、基于机器学习的动作识别以及基于深度学习的动作识别。基于规则的动作识别指的是在识别过程中,使用预先设定的规则来进行推理和决策。
关于人体姿态、动作识别的资料集
1、D、3D姿态识别 非常强大,很适合入门,通读后再对具体细节进行深究。还介绍了动作识别:要识别出人物的动作通常需要连续的视频数据进行分析处理,需要采集的特征通常有单帧图像数据的特征和多帧图像数据之间时间上的特征,简单来说就是静态帧数据+ 帧间数据 。
2、就广义而言,人体运动分析的研究对象既可以是以人脸、唇、手势等为代表的较小尺度的局部人体运动;也可以是手臂、腿部或全身等人尺度的全身或肢体运动。前者,例如在人脸识别中,通过对人脸的运动分析,跟踪人脸在空间姿态和位置,可以定位人脸,从而为进一步的人脸识别做基础。
3、人体姿态识别作为行为监控的重要参考,已经广泛应用于视频采集、计算机图形学等领域。其中,传统的人体姿态识别方法有RMPE模型和掩膜R-CNN模型,这两种方法都是自顶向下的检测方法。
4、本次主要介绍基于人体骨架的姿态重建。 目前工业界已有相对成熟的三维姿态重建解决方案,即接触式的动作捕捉系统,例如著名的光学动作捕捉系统Vicon(图1)。首先将特制的光学标记点(Marker)贴附在人体的关键部位(如人体的关节处),多个特殊的动作捕捉相机可以从不同角度实时检测Marker点。